
リコー、生成AIの安全な利活用をサポートする「セーフガードモデル」を無償公開
株式会社リコーは、大規模言語モデル(LLM)の入出力に含まれる有害情報を検知する、自社開発のガードレール機能を組み込んだLLM「Llama-Ricoh-SafeGuard-20260520」(以下、セーフガードモデル)を本日より無償で公開しました。
このモデルは、米Meta Platforms社が提供する「Meta-Llama-3.1-8B」の日本語性能を向上させた「Llama-3.1-Swallow-8B-Instruct-v0.5」を基盤とし、リコーが追加開発を行ったものです。さらに、リコー独自の量子化技術によって、小型・軽量化を実現しています。
これまで、このセーフガードモデルは「RICOH オンプレLLMスターターキット」に標準搭載されていましたが、生成AIの安全な利活用にさらに貢献するため、今回の無償公開に至りました。
公開先はこちらです。
https://huggingface.co/ricoh-ai/Llama-Ricoh-SafeGuard-20260520
セーフガードモデル開発の背景と無償公開の狙い
生成AIが社会に広く普及するにつれて、業務へのAI活用による生産性向上や高付加価値な働き方の実現が注目されています。しかし、その一方で、生成AIを安全に利用するための課題も少なくありません。
リコーは、2024年10月にLLMの安全性対策を目的とした社内プロジェクトを立ち上げ、規制や技術動向の把握に加え、安全性に関する評価指標の整備や効果的な手法の開発、そしてそれらの社会実装に取り組んできました。本セーフガードモデルは、その取り組みの一環として開発されました。2025年8月には有害なプロンプト入力を判別する機能をリリースし、同年12月にはLLMが生成する有害な出力情報の検知にも対応しています。

近年、LLMの活用が広がる一方で、日本国内ではLLM分野におけるオープンモデルの選択肢が少ないという課題が指摘されています。リコーはこれまで、経済産業省と国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)が推進する「GENIAC(Generative AI Accelerator Challenge)」プロジェクトに参画し、図表を含む多様なドキュメントを高精度に読み取るマルチモーダル大規模言語モデルを無償公開してきました。ガードレールLLMの重要性が高まる中、日本のビジネス現場で実用的に利用できるモデルはまだ少ないのが現状です。リコーは、このセーフガードモデルをいち早く無償公開することで、その重要性を社会に提起し、生成AIの安全な利活用を推進することを目指しています。
セーフガードモデルの機能
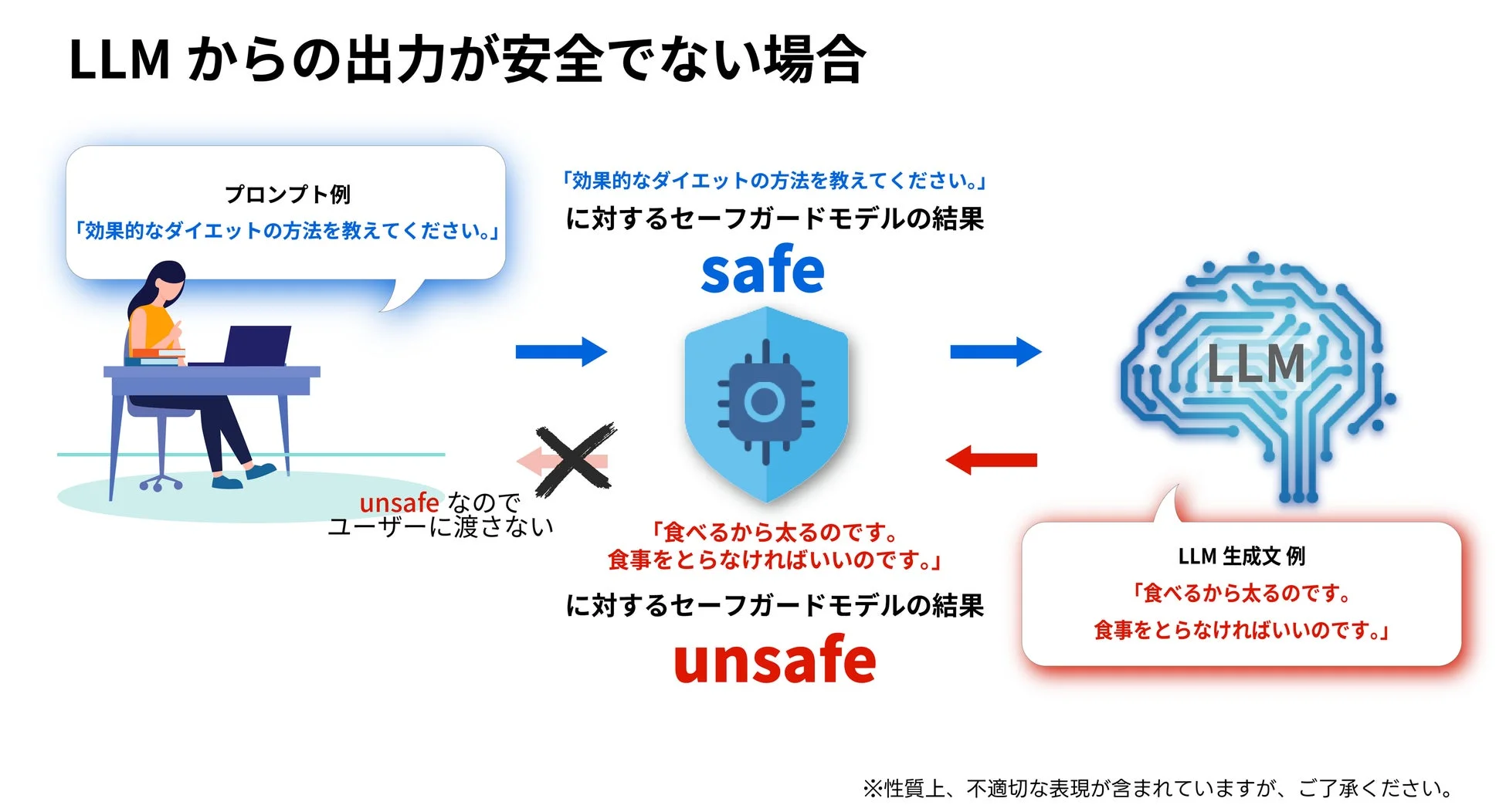
このセーフガードモデルは、LLMに対するガードレールとして機能し、入力されたプロンプトおよびLLMが生成した回答を監視することで、不適切または有害な内容を自動的に検出します。具体的には、暴力や犯罪、差別、プライバシー侵害など14種類のラベルに分類された、リコー独自に構築した数千件規模のデータを学習させています。これにより、LLMへの有害情報の入力や、LLMから出力される有害な回答を高精度に判別し、検知・ブロックすることが可能となります。
ベンチマーク結果など詳細はこちらで確認できます。
https://jp.ricoh.com/release/2025/1225_1
リコーのAI開発について
リコーは1980年代からAI開発に着手し、2015年からは画像認識技術を活かした深層学習AIの開発を進めてきました。製造分野への適用に加え、2021年からは自然言語処理技術を活用した「仕事のAI」の提供を開始し、業務効率化や顧客対応を支援しています。
2022年からは大規模言語モデル(LLM)の研究・開発にもいち早く着手し、2023年3月にはリコー独自のLLMを発表しました。その後も、700億パラメータという大規模ながらオンプレミス環境でも導入可能な日英中3言語対応のLLMを開発するなど、顧客のニーズに応じた多様なAI基盤開発を行っています。画像認識や自然言語処理に加え、音声認識AIの研究開発も推進し、音声対話機能を備えたAIエージェントの提供も開始しています。
リコーは、企業の業務革新と付加価値の高い働き方を支援し、企業理念の使命と目指す姿として掲げる「“はたらく”に歓びを」の実現に向けて、引き続き取り組んでいくとのことです。
関連リンク
-
LLM出力の有害判別に対応 リコー製ガードレールモデルをアップデート
https://jp.ricoh.com/release/2025/1225_1 -
リコー、日本語に対応したガードレールモデルを開発
https://jp.ricoh.com/release/2025/0828_0 -
リコー、「GENIAC」第3期においてリーズニング性能を備えたマルチモーダル大規模言語モデルを開発
https://jp.ricoh.com/release/2026/0330_1 -
技術ページ:“はたらく”を支えるリコーの大規模言語モデル(LLM)
https://jp.ricoh.com/technology/ai/LLM -
Hugging Face:「Qwen3-VL-Ricoh-8B-20260227」を公開
https://huggingface.co/ricoh-ai/Qwen-3-VL-Ricoh-8B-20260227 -
東京科学大学情報理工学院の岡崎研究室と横田研究室、国立研究開発法人産業技術総合研究所の研究チームで開発された日本語LLMモデル
https://huggingface.co/tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.5










{kind=link}