
全二重型音声対話モデルの技術的特徴
① 対話と業務実行の同時処理
このモデルの最大の特徴は、人の発話の途中からでも意図を捉え、応答生成や業務処理を即座に開始できる点にあります。従来の音声AIが発話完了を待ってから処理を開始していたのに対し、本モデルは発話中から並行して処理を進めるため、まるで人間同士のようなリアルタイムな会話応答が可能です。
例えば、雑談では会話の盛り上がりに応じて応答を即時に変化させたり、仕事の相談では確認応答に加え、笑い声などの非言語表現もリアルタイムで生成したりします。また、旅行の相談では相槌のタイミングと強度を自然に制御し、落ち着いた対話を維持するといった使い方が想定されます。
② 目の前の情報を認識する画像理解
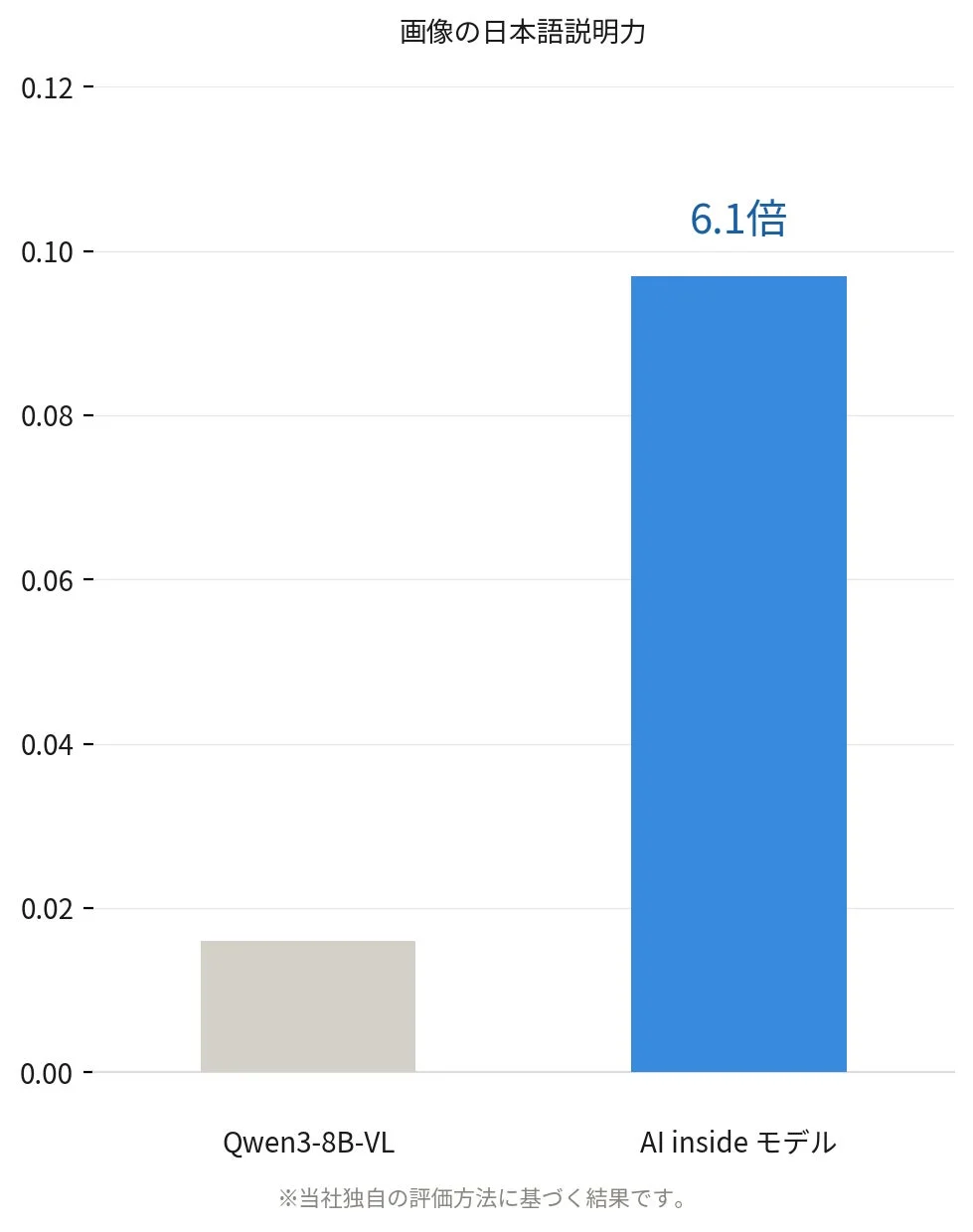
画像・音声・テキストを一つのモデルで統合的に処理する仕組みも実現しました。画像内容を日本語で説明する評価では、既存のQwen3-8B-VLと比較して約6.1倍の説明精度が確認されています。この画像理解能力は、帳票や書類などの画像情報を認識し、音声指示と組み合わせて業務を実行する「業務完遂AIの目」として機能します。

開発手法と業務完遂AIの実証
本研究では、日本語理解などの基礎能力を活かしつつ、必要な部分のみを追加学習する手法が採用されました。これにより、モデル全体を作り直すことなく性能を向上させ、既存の業務環境や用途に迅速に適応できる設計となっています。この拡張性により、エッジコンピュータ「AI inside Cube」上での展開や既存プロダクトへの組み込みにも適していると考えられます。
実証では、自社AIエージェント基盤と連携し、音声指示と帳票情報を組み合わせた業務プロセスが自律的に実行されました。その結果、従来人手で行っていた業務の完了時間を96%短縮できることが確認されています。これは、AIが業務プロセス全体を自律的に完遂し、人の介入を最小限に抑えた業務実行が可能であることを示しています。
研究成果の社会実装とAI insideのビジョン
今回開発されたモデルは今後、商用バージョンへのアップデートが予定されており、音声会話モデルや各種サービスへの展開が進められるでしょう。AI insideは、この研究開発の成果を基盤として、音声を含むマルチモーダル生成AIの研究開発と社会実装を継続的に推進していく方針です。
「No more tools, work with buddy」という理念のもと、AIを単なるツールとしてではなく、人と共に考え判断を支える存在へと進化させ、日常から業務まで幅広い領域での活用を目指しています。
AI inside株式会社に関する詳細情報は、以下のリンクから確認できます。
※文中の製品またはサービスなどの名称は、AI inside 株式会社の商標または登録商標です。










{kind=link}